Mayores 18 años


El análisis de datos es un proceso que consiste en partir de un conjunto de datos y trabajar sobre estos para obtener información de ellos y poder sugerir conclusiones o apoyarnos en la toma de decisiones. Es un campo candente a día de hoy el cual brinda muchas comodidades y facilita nuestra vida sin embargo es probable que no nos demos cuenta de su aplicación si no conocemos sus técnicas.
![]()
Existen los siguientes tipos de problemas dentro de la ciencia de datos:
![]()
![]()
![]()

A continuación veremos un algoritmo que se suele emplear mucho en tiendas y supermercados sin que nos demos cuenta, de hecho a este algoritmo se le conoce como el algoritmo de la cesta de la compra.
Para entender el resultado de este algoritmo basta con dar una vuelta por los pasillos de un supermercado. Es muy probable que cerca de donde esté la pasta se encuentre el tomate frito o que el agua y la leche también se ubiquen en la misma zona, es esto casualidad o no nos preguntaremos y como se viene atisbando la respuesta es no.
El algoritmo apriori parte de una serie de transacciones, es decir, conjuntos de elementos y se encarga de buscar relaciones de asociación entre estos conjuntos. En el caso del supermercado,partimos de un conjunto de tickets de la compra de los diferentes clientes y a partir de estos obtenemos una serie de reglas que nos indican los productos que se compran en conjunto.
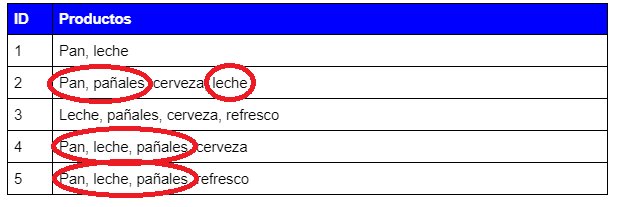
Supongamos la siguiente lista de transacciones:
![]()
| Id | Productos |
|---|---|
| 1 | Pan, Leche |
| 2 | Pan, pañales, cerveza, leche |
| 3 | Leche, pañales, cerveza, refresco |
| 4 | Pan, leche, pañales, cerveza |
| 5 | Pan, leche, pañales, refresco |
![]()
Hay que encontrar las reglas que predicen la compra de un producto en base a los otros, para ello a continuación presentamos 3 términos que son importantes en el desarrollo del algoritmo
Support, indica popularidad del producto, se calcula dividiendo el número de transacciones en las que aparece el subconjunto de productos partido del total de transacciones, por ejemplo
Support( {Pan, Pañales, Leche} )= 3/5
![]()
Confidence, indica la probabilidad de que se compre un producto B si se ha comprado un producto A y se calcula dividiendo el número de transacciones donde se ha comprado A y B juntos partido del número de transacciones donde se compra A. Por ejemplo,
![]()
Confidence( Pan → Leche )= 4/4=1
![]()

Lift, indica el aumento de ventas de un producto B cuando se vende el producto A y se calcula de la siguiente forma:
![]()
Lift( Pan → Leche )= confidence( pan → leche) / support(leche)=1 / ⅘ = 5/4
![]()
Como el algoritmo intenta sacar reglas para todos los subconjuntos de los productos, para evitar el problema del coste computacional se definen unos límites inferiores tanto para el support como para la confidence y sólo trabajamos con las reglas que superen este límite ordenadas decrecientemente usando el lift.
![]()
Los pasos que se llevan a cabo son los siguientes (suponiendo un mínimo de ⅖ de soporte):
Soporte para los productos individuales:
![]()
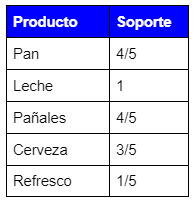
![]()
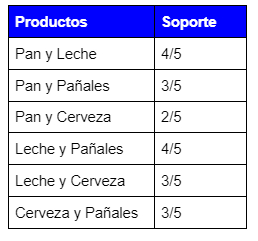
El refresco no cumple con el soporte mínimo por lo tanto se poda. Y se comprueba el soporte con la lista de productos de tamaño 2:
![]()
Y de tamaño 3:![]()
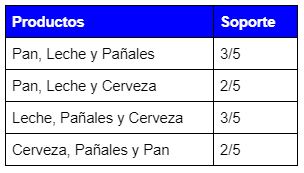
![]()
Pero los subconjuntos Pan y Cerveza son infrecuentes porque no superan el soporte mínimo, por lo tanto obtenemos los siguientes subconjuntos de orden 3:

![]()
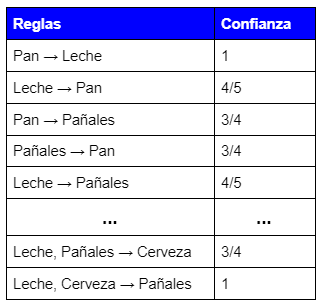
A continuación se crean las reglas de asociación a partir de los conjuntos frecuentes de la siguiente forma:
![]()
![]()
Por ejemplo reglas que no superen el 70% de la confianza
![]()
![]()
A continuación realizaremos un ejemplo con un dataset más grande y usaremos python y la biblioteca apyori para ejecutar el algoritmo.
https://stackabuse.com/association-rule-mining-via-apriori-algorithm-in-python
Para profundizar fp-growth.
Este tutorial ha sido desarrollado por Óscar Cabrera, graduado en matemáticas e informática, durante el programa de becas de formación práctica en 2021 del cabildo de Fuerteventura.
